If you are already working with Applied Data Science in a professional capacity, you will be well aware that Covid-19 has disrupted most data forecasting, analysis and segmentation models. It would not be an exaggeration to say that even base assumptions have been shaken, as the world recalibrates life after country lockdowns affected global supply chains, demand cycles, traffic flow and consumer behaviour patterns.
As countries start out on their recovery journeys, data scientists will be in great demand to track how demand returns and to gather insights into what the revised baselines should be. In many cases there may be a need to practically overhaul the forecasting algorithms that were put in place in pre-Covid-19 days. In other words, it may be time to brush up on all the theories they taught you in data analytic courses.
Is there a model drift?
If the variances in data flow impact the process built into the data science system, there will be a pressing need to revamp the data science models adopted. Data science teams across enterprises have already returned to the drawing boards to check if there has been a model drift. Model drift happens when there is not enough predictive maintenance, performance monitoring and automatic retraining built into the system.
If experts who wrote the code initially are not around now to “update” the baseline assumptions or if your systems are not equipped with sophisticated automated machine learning tools to do an upgrade, it is clear that the data science model needs a revisit.
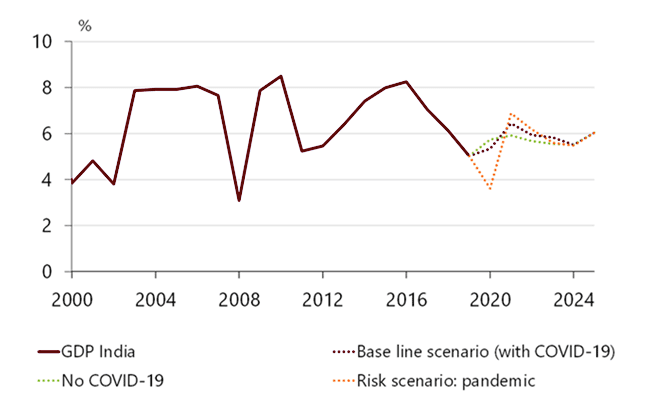
Remodelling post Covid-19 is a very distinct possibility in many sectors like airlines,insurance and health supplies where historical data and predictive analytics don’t work like before.Cancellations, one-way bookings, risk profiles, demand spikes have brought in new and unseen data which demands fresh categorisation and labelling.
It is also possible to find a data science vs data analytics mismatch as the dependencies extracted may change. In which case, a fair amount of retraining or reassembling of data sets is called for. As companies rush to boost their data science talent pool, there is a surge in searches for data analytics courses online.
Fresh Data Challenges Ahead
Of course you will see a spike in data analyst salary levels and HR demand for resumes that feature a certification in data analytics.
Businesses everywhere will be doing the following on high priority:
- Update data science and data analytics models to handle new and unseen data
- Reassemble existing data models to arrest concept drift
- Facilitate a shift to adaptive AI-ML-DL models which can be developed, deployed and managed with agility to handle frequent changes to environment.